「心地よいデータマイニング3つの掟」と題し、データマイニングの定義にはじまり、ビジネスへの応用、アルゴリズムの解説まで全10回にわたる、データアナリティクスについての連載です。第3回目となる今回は、「データマイニング手法の実際」と題し、解説していきます。
さて、今回は前回ご紹介したデータマイニング手法「CRISP-DM」の後半として、引き続きフェーズ4「モデル作成」から解説します。
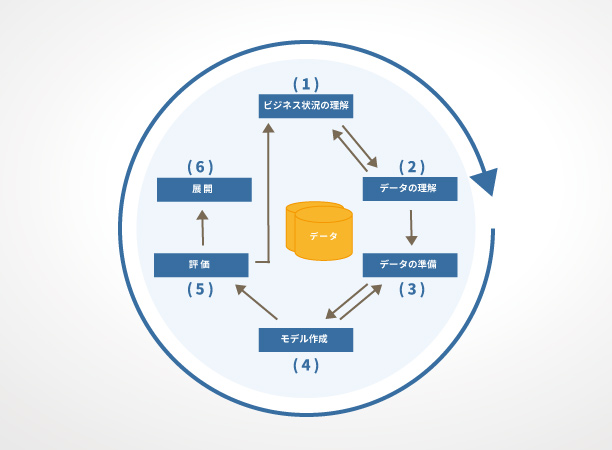
図1:CRISP-DM概要
―フェーズ4― モデル作成
前回では、マイニングをおこなうにあたり、フェーズ1、ビジネスの課題と目標を設定すること。フェーズ2・3、データの理解と準備には工数の70%~80%を費やすこと。これらのフェーズが重要であることを書いてきました。ここまで作業が進むことができれば、次はそのデータに対し、「モデル」を選択して分析を実行していくことになります。なお、マイニングモデルの詳細については、このデータマイニングのすべてのフェーズを解説した後に解説します。
それでは、モデル作成フェーズの概要を見てみましょう。
まず、モデルは幾つかのカテゴリーに分けることができます。「パターン発見」「予測」「分類」の3つです。これらカテゴリーにそれぞれアルゴリズム(*1)を持ったモデルがあるので、ビジネスの課題解決と目標達成を考えながら使用するモデルを選択して行きます。よく使われるものは、以下のものです。
パターン発見: マーケットバスケット分析(*2)
予測: 回帰分析(*3)、ニューラルネットワーク(*4)
決定木(ディシジョンツリー)(*5)
分類: クラスター分析(*6)
前回でもご紹介したIBM SPSS Modeler には、先に書いたモデルも含めさまざまなモデルが用意されています。そしてこれらは機械学習、人工知能、統計などの技術よって実現され、データを分析し、予測モデルを作成できます。
余談ですが、ニューラルネットワーク(Neural network 神経回路網)はその名称から、人間の脳機能に見られるいくつかの特性をコンピュータの計算によって表現することを目指したモデルです。研究の始まりは人の脳のモデル化でした。 コンピュータのプロセッサーの進化により、2018年にはコンピュータは人間の脳に追いつくという説もあり、演算処理能力という意味では、人口知能が人間に勝る日も近いのではないかと感じます。
話をマイニングのモデルに戻します。先述のとおりマイニングのモデルには様々な種類があり、それぞれ特徴や長所・短所があります。それぞれ万能ではないので、いくつものモデルを試してみて、目標に対して適切な結果が出るものを採用するとよいかもしれません。しかしながら、試行錯誤は手間と時間を要します。
IBM SPSS Modelerは、対象のデータに対して複数のモデルを作成し比較する機能があり、最適なモデルを自動的に導き出してくれます。Yes/Noや1/0などの二種類のデータの場合は「自動分類ノード」(*7)、連続する数値データの場合は「自動数値ノード」(*7)を使用します。これにより、思考錯誤の手間と時間を省くことができます。
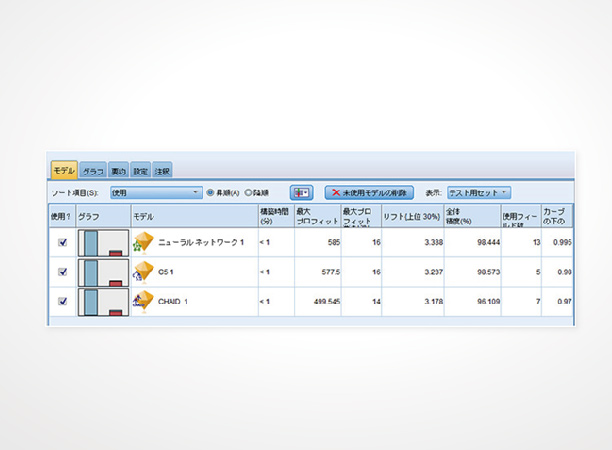
データの準備フェーズまで行った後で、どのモデルでマイニングを行うか?という検討についてひとつ参考ケースを紹介します。データの準備を完了し、マイニングにおいてどのモデルを採用するか、という段階での話です。
プロジェクトに参加しているメンバーは業務経験が長いメンバー、データマイニングのトレーニングを受け、一定のアルゴリズムの知識も身につけたメンバーなど。それぞれの持論を主張し、なかなか結論にたどり着きません。マニュアルやトレーニングの資料などを元に選択したのは、自動数値ノードとこの件における「最適」とみなすモデルでした。結果、自動数値ノードはうまくはまり、ビジネス・業務にも結果をフィードバックすることができました。先ほど、手間・時間を省くメリットについて言及しましたが、「自動」対応を選択するメリットはスピード感の維持にも役に立ちます。迅速な分析と意思決定が可能となるため、ビジネスは加速。「心地良いアナリティクス」の実現に役立ちました。
「モデル」「アルゴリズム」「人口知能」などの言葉が並ぶと、どうしてもデータマイニングへの敷居が高くなってしまうかもしれませんが、このモデル作成のフェーズはマイニングツールの進化もあり、非常に使い勝手が良くなっている部分です。マウス操作だけでモデルの選択と設定ができるので、この部分だけを見てしまうと専門家でなくてもデータマイニングは簡単にできるのではないか?なんて勘違いされることもあることでしょう。
*1 数学、コンピューティング、言語学、あるいは関連する分野において、問題を解くための手順を定式化した形で表現したもの(wikipedia)
*2 よく一緒に買われる商品を見つけるためのデータ分析(wikipedia)
*3 従属変数(目的変数)と連続尺度の独立変数(説明変数)の間に式を当てはめ、従属変数が説明変数によってどれくらい説明できるのかを定量的に分析すること
例えば消費が従属変数、国民所得が独立変数としたとき国民所得の変化がどう消費に影響するか予測する(wikipedia)
*4 脳機能に見られるいくつかの特性を計算機上のシミュレーションによって表現することを目指した数学モデル(wikipedia)。人間の脳と同じように、物事を記憶し、インプットデータは、その記憶に従った判断が行われた後でアウトプットされるしくみ。
*5 とりうる選択肢や起こりうるシナリオすべてを樹形図の形で洗い出し、それぞれの選択肢の期待値を比較検討した上で、実際にとるべき選択肢を決定する手法(コトバンク)
*6 与えられたデータを外的基準なしに自動的に分類する手法(wikipedia)
―フェーズ5― 評価
モデル作成とその実行が終わったあとは、いよいよ評価です。ビジネスの課題は解決できる分析結果になったのか?それで目標は達成できるのか?という視点で評価していきます。
そのためにも、CRISP-DMの「フェーズ1:ビジネス状況の理解」で設定した「課題と目標」はどうだったのか?複数人のプロジェクトでマイニングを行う場合、このフェーズ1で関わったメンバーに評価をしてもらうとよいと思います。「面白い結果が出た」とデータの結果が出たことに対して満足するではなく、モデル作成・実行の結果をビジネス・業務への展開につなげていくことが重要です。
また、データマイニングは前回解説したCRISP-DMの通り、サイクルが完了したらその次のサイクル、というように各フェーズそれぞれプロセスを繰り返しおこなうことでより精度が向上します。
マイニングの対象となるデータは常に変化します。例えば、顧客の数、顧客層、商品の種類や数、売れる時間帯等々、それらの変化の幅と時間はどんどん大きく、どんどん速くなってきています。従って、変化に迅速に対応するという観点からもマイニングを繰り返すことはとても重要です。
―フェーズ6― 展開
このフェーズでは、実施したデータマイニングの結果をビジネス・業務に適用し展開していきます。
業務に適用する際、重要なポイントとなってくるのは 業務の現場部門およびメンバーからの協力です。
そのためにもマイニングにおけるプロジェクトメンバーには必ず現場のメンバーも加え、フェーズ1のビジネス理解に加え、この展開フェーズでも力を発揮してもらう体制が必要です。せっかく秀逸なマイニングができたとしても、ビジネス・業務に適用できなければ画餅に終わります。体制をどうすべきかについては次回以降、改めて詳細に触れたいと思います。
分析した結果を元に施策として展開した例を見てみることにしましょう。
ある会員制の通信販売の企業で、退会率を下げたい、という目標設定を掲げていました。そのケースでは、まずそれまでに退会した会員の購買履歴データから決定木(*7)のグラフを用いその傾向と要因を突き止めました。次いで、導き出した購買傾向に類似する現会員をリストアップし、その可能性を確率として算出します。そして、退会確率の高い順から特別優待のキャンペーンなど、リテンション施策を実施することで退会を予防する、というアプローチをおこなうことができます。これらで用いた退会するか否かや、その確信度計算はIBM SPSS Modelerが自動的に処理してくれます。
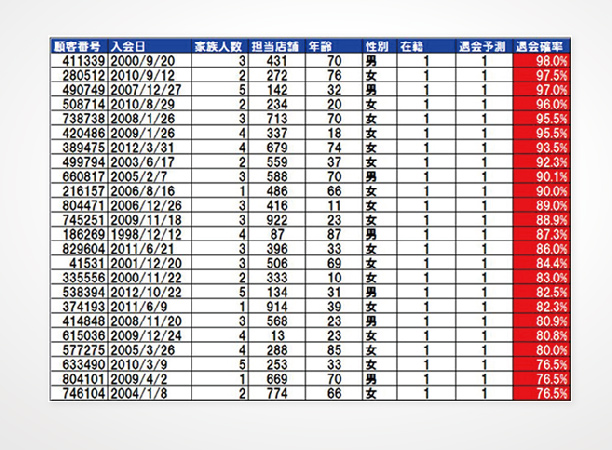
図3:マイニングを行った結果、現会員で退会すると予測された会員一覧(イメージ)
また、繰り返しになりますが、展開後も課題は解決したか、目標は達成できたか、を判断の上、新しいデータの追加、モデルの選択などを行い、再度評価し、業務へ展開する、というサイクルを繰り返すことが重要です。
もちろん、市場や顧客の変化に伴い課題や目標もすぐに変化しますので、データマイニングもスピードをもって変化しなければなりません。そういう意味では「終わりなき戦い」ではありますが「競合に勝つ戦い」の一つがスピードをもったデータマイニングのビジネスへの実装と言えます。
*7 IBM SPSS Modelerの機能。多くの異なるモデルを作成および比較し、与えられた分析への最善のアプローチを選ぶことができる。
今回はデータマイニング手法「CRISP-DM」の後半について説明いたしました。ここまでは手法に関する内容を説明してきましたが、次回は少し切り口を変え、実際のデータマイニングプロジェクトを進めるにあたっての必要なものは何かをお伝えしていく予定です。プロジェクトを進めるための「3つの掟」とはなんなのか、ご期待ください。