「心地よいデータマイニング3つの掟」と題し、データマイニングの定義にはじまり、ビジネスへの応用、アルゴリズムの解説まで全10回にわたる、データアナリティクスについての連載です。第2回目となる今回は、「アナリティクスをビジネスに役立てるには」と題し、解説していきます。
データマイニングを実施する方法とポイント
データマイニングを進めて行く方法を示したモデルのひとつが「CRISP-DM」(CRoss-Industry Standard Process Data Mining)です。現在、データマイニングを行う際にもっとも多く使用されています。
このモデルは1996年に考案され、SPSS、テラデータ 、 ダイムラーAG 、 NCRコーポレーションとOHRA の5社の主導により規定・標準化されました。(*1)
このモデルは全部で6つのフェーズでデータマイニングを進めるように定義されています。(図1)
フェーズ1:ビジネス状況の理解 (BUSINESSES UNDERSTANDINGS)
フェーズ2:データの理解 (DATA UNDERSTANDINGS)
フェーズ3:データの準備 (DATA PREPARATION)
フェーズ4:モデル作成 (MODELING)
フェーズ5:評価 (EVALUATION)
フェーズ6:展開 (DEPLOYMENT)
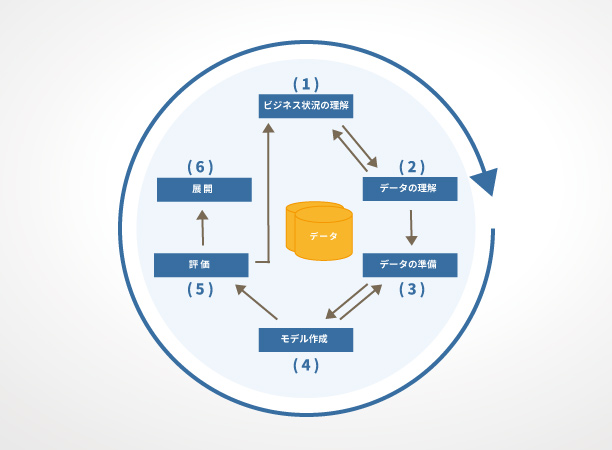
図1:CRISP=DM概要
図1に示されているように、これらのフェーズは一度だけ実行するのではなく、繰り返し実行し、マイニング結果の精度を高めて行きます。例えば新製品や新規マーケットなどのマイニング対象要素の追加・変更があればそれらを含めながら、繰り返しマイニングを行っていきます。
*1 wikipediaを参照のこと。
―フェーズ1― ビジネスの状況の理解
データマイニングといっても、クイズを解くわけでもなく、ゲームでもありません。結果として何かしらの予測ができたとしても、ビジネスに効果をもたらさないと意味がありません。
そこで、まずは現状のビジネスの状況を「理解する」ところから始める必要があります。フェーズの名称が「ビジネス状況の把握」ではなく「ビジネス状況の理解」であることがポイントです。つまり、ここで一番重要なのは、ビジネスを理解した上でその「課題」と改善・解決の指標である「目標」を定めることです。(資料によっては「把握」と表現しているものもあります)
データマイニングを進めるためには、「課題」と「目標」があることが大前提です。
ひとつ例を見ていきましょう。
データマイニングプロジェクトの提案に際したヒアリング時におけるお客様からの発言です。
「データはあるし、データの内容も理解している。このデータを活用し、いま進めているプロジェクトの立ち上げを承認してもらうために、会社を説得できる“何か”をアウトプットしてほしい。できれば会社が気づいていない併売パターンとかがよい。」
この発言はまさに、ビジネスの課題と目標を明確に定めていないからこそ生じる発言です。本連載の第1回目でも解説しましたが、データマイニングは「魔法の箱」ではありません。
このような「課題と目標」が明確になっていないケースは少なくありません。そして、このような場合、データマイニングは「魔法をかけられない」ため、おこなわれることなく、結果としてプロジェクトが開始されることはまずありません。
ビジネスの課題と目標は何なのか。これをまずは定義すべきです。
目標は具体的な数値であること望ましく、実際に売上や利益に結びつけねばなりません。
たとえば、「会員の退会率を10%減らす」という目標を立てたとします。この場合、さらに踏み込み、結果として会員がXX人継続し、XXXX万円の利益が見込める。結果として売上はXX%増加する。という具合です。もちろん、課題と目標がなければ、マイニングの結果がアウトプットされたときに、それに対する評価ができず、意思決定ができないというのは言うまでもないでしょう。
―フェーズ2― データの理解
データマイニングにおいて次に重要になるのが、データに関する2つのフェーズです。
データについての「理解」と「準備」、2つのフェーズでデータマイニングの工数の70%~80%が費やされると言われています。
まずはデータの理解からですが、ここではマイニングの対象とするデータが使えるか否かを吟味します。
主には、データ項目と属性、データ量、そして品質です。特に品質を左右するものとして、外れ値(データ分布の中でかけ離れた値を持つもの)、欠損値(ブランクデータ、NULL)、異常値(入力ミスデータ)などがあり、取り扱うデータの品質がフェーズ1で定めた目標に対する分析を実施できるかどうかを精査せねばなりません。
精査に当たり対象データの全レコードとは言わずとも、実際にマイニングを手掛ける担当者による「データを眺める」ことをお勧めします。これを「基礎俯瞰」と呼んでいます。もし全体のデータ量が多いときは、トランザクションの多い時間帯・時期のものを選ぶなど、見方を工夫をするとよいでしょう。データの状況次第で、目標の再定義やデータマイニング自体の再考も視野に入れることになります。
―フェーズ3- データの準備
データの理解が完了した次はデータの準備のフェーズです。ここではデータを分析に使える形にする、いわゆるデータクレンジングを実施します。前述の基礎俯瞰の結果も考慮に入れて行います。
代表的な作業を以下挙げていきます。
■空白や欠損値の削除または置換
欠損値は意味があっての空白値とそうでない場合があります。意味がある場合は意味があるように値を置換しておく必要があります。また、欠損値をゼロにすることが無理な場合、その割合をどこまで許容するかも見定めておくとよいでしょう。
■サンプルのデータの選択
データの規模・量によってデータ件数を減らすことも必要になります。これによりマイニング実行時のパフォーマンスを上げることができます。
ただし無作為にデータ件数を減らしてはいけない場合もあります。例えば、クライアントごとの年間を通した月ごとの売上など、ある期間を通してデータが順序(シーケンス)を持って変化するものをマイニングしなければならない場合などはサンプリングをすべきではありません。
現在はIBM SPSS Modeler(*2)のように、マイニング処理だけを抜き出して高速なサーバーに処理させる機能を持つマイニングツールもあるので、無理なサンプリングをして役に立たないマイニングをおこなうことは避けるべきと考えます。大量のデータを高速に自動的に処理する機能がさらに拡張して行くことにより、さらにマイニングが身近なものになっていくことでしょう。
*2 IBMのマイニングソフトウェア。2009年IBMがSPSSを買収し現在に至る。旧製品名はSPSS Clementine。
■データの加工
全角・半角などの形を整えるのはもちろん、例えば一人の顧客に関連する項目を結合させ、別のフィールドを作成するなど、マイニングの目標に従ったデータ加工を行います。IBM SPSS Modelerでは、CLEM(Clementine Language for Expression Manipulation)言語により、このデータ加工作業を容易にしています。
このように書いていくと、データの準備は相当な手間がかかるように思われるかもしれません。
しかしながら、例えば先述のIBM SPSS Modelerにはデータ自動準備機能もあり、有用でないフィールドの除外、データ分析および修正部分の特定などをしてデータの準備に関する手間を省くことができ、データマイニング全体の工数削減を実現します。
一見、データの理解と準備は手間がかかったり、難易度が高いケースもありますが、マイニングに使用するデータのうちメインのデータが一つのサーバーに格納されており、かつ、普段の業務の中でそのデータを参照したり集計する仕組みがすでに存在するならば、データマイニングのプロジェクトは進めやすい状況と考えられます。実際のケースを2つご紹介します。
1つめは業務に関わる全てのデータをこのIBM iの中に格納していたケース。このケースではIBM iの内部でデータを加工してしまう仕組みにすることで、マイニングツールはそれを読み込み処理するだけです。
2つめはPOSデータをすべてIBM iに蓄積していたケース。このケースでは、蓄積したデータを検索・置換しエクセルに抽出するツール「WebReport2.0(*3)」を利用しており、マイニングにふさわしいクレンジングされたデータをすぐに用意することができる状況でした。結果、データマイニングのプロジェクトは迅速に立ち上がりました。
もちろんこのような環境は稀で、上記のような場合でも、マイニングを進めて行く中で、他のサーバーのデータを追加するケースもあります。そういった場合は、基本に立ち返り、データの理解とデータの準備のフェーズを丹念に進めて行くことになります。
*3 JBアドバンスト・テクノロジー株式会社(JBCCホールディングス株式会社の事業会社)が
開発する、データを利活用するためのBIツール。データベースに関する専門的な知識が無くて
も、情報系/基幹系データベースから、データを抽出でき、様々なグラフを作成。見やすいレポ
ートを作成できる。操作性の良さもあり、上記IBM iと合わせて使用するお客様が多い。
データサイエンティストに未来はあるか

「データサイエンティストは消滅する」という説もあるように、マイニングツールの操作性は日々進化し、誰でも扱えるというのも過言ではないでしょう。エクセルの分析機能も進化してきており、マイニングツールの操作を行うという部分では専門家でなくてもマイニングができます。
しかしながら今回説明してきた、ビジネスの理解からデータ準備までは「データサイエンティスト」に該当する担当者もしくは担当チームがないと成り立ちません。なぜなら、先述したように、データマイニングの工数の70%~80%がデータの理解と準備で費やされ、かつ、このフェーズの作業を疎かにすると、いくらマイニングツールの操作性や機能が優れていても、役立つ結果がアウトプットできなくなるためです。データマイニングの業務において意見、非常に地味に見えてしまうフェーズではありますが、この1~3が重要であることがご理解いただけたのではないでしょうか。
次回は今回の続きとなる、フェーズ4のモデル作成から入ります。マイニングを行った結果、課題を解決する原因がわかったり、意外な法則が見つかったりした事例なども含め説明していきます。