前回の記事の後編として、配列データ型とそれに関連するSQL関数に関する記事をお送りします。今回は、配列変数と表を相互に変換するための新しいSQL関数を使った処理の例やJavaによる配列パラメータの受け渡し例、SQL配列を使ったプロシージャのデバッグ法など、より実践的な内容を具体例と共にお届けします。(編集部)
この記事では、配列データ型の定義プロセス、SQL PLとJava両者における配列の作成、そして新しいSQL関数を使った配列変数の操作について説明します。

07/01/2010 トム・バルマー
UNNESTで配列を表に変換する
UNNEST関数は、1つ以上の配列変数またはパラメータを入力引数として受け入れ、値が代入された各配列要素に対して1行をもつ表を返します。表の行数は、全入力引数の中の最大多重度に等しくなります。NULL配列は空の配列と同様に扱われます。
SQLの表関数に馴染みがあるなら、UNNESTはVALUES文とユーザー定義表関数(UDTF: User Defined Table Function)の中間のどこかに位置付けられます。データベース・エンジンは一時表を実際に作成する必要はなく、単に配列要素をあたかも表の行のように取り出す抽象化を使用するだけです。
下のコード例3の簡単なプロシージャは、SQLの結果セットとして配列を返すUNNEST関数を使った例を含んでいます。それは配列コンストラクターと別のプロシージャに配列を渡す単純な例でもあります。
testWeekends create or replace procedure testWeekends dynamic result sets 1 begin declare dates dateArray; declare weekends dateArray; -- 配列の内容を表として返す declare cr cursor with return for select dateColumn, DAYNAME(dateColumn) as name from UNNEST(weekends) as weekendTable(dateColumn); set dates = ARRAY['2004-01-01', '2005-01-01','2006-01-01', '2007-01-01']; call getWeekends(dates, weekends); -- 期待される結果: 2005-01-01, 2006-01-01 open cr; end;
▲コード例3
プロシージャの呼び出しはUNNESTクエリを実行し、配列変数weekendsの内容をもつ結果セットを返します。
| DATECOLUMN | NAME |
|---|---|
| 2005-01-01 | Saturday |
| 2006-01-01 | Sunday |
UNNEST関数にはオプションのWITH ORDINALITY節があります。WITH ORDINALITY節が含まれている場合、表には各行に対する現在の副指標(配列要素の順序番号)の値をもつ追加の列を含みます。下記のコード例4は1つの順序列と複数の入力配列を使ったUNNESTの振る舞いを示しています。
doUnnest CREATE TYPE dateArray AS DATE ARRAY[100]; CREATE TYPE myArray AS INT ARRAY[100]; CREATE TYPE stateList AS CHAR(2) ARRAY[50]; create or replace procedure doUnnest dynamic result sets 1 begin declare myDates dateArray; declare myArray intArray; declare states stateList; declare cr cursor with return for select dates, ints, states, ordinality from UNNEST(myDates, myArray, states) WITH ORDINALITY AS myTable(dates, ints, states, ordinality) where substr(states, 1, 1) = 'M' set myDates = ARRAY['1985-05-22', null, null, '2009-06-02']; set myArray = null; set states = ARRAY['MA', 'ME', 'WI', 'MI', 'MN']; open cr; end; call doUnnest;
▲コード例4
プロシージャを呼び出すと、順序列を含めすべての配列データをもつSQL結果セットが返されます。UNNESTに対する入力引数の多重度が等しくない場合、短い方の配列はNULL要素で「充填」されます。
| DATES | INTS | STATES | ORDINALITY |
|---|---|---|---|
| 1985-05-22 | – | MA | 1 |
| – | – | ME | 2 |
| 2009-06-02 | – | MI | 4 |
| – | – | MN | 5 |
ARRAY_AGGで表を配列に変換する
クエリの結果を配列出力に変換する必要のあるプロシージャは、ARRAY_AGG集約関数を活用することができます。ARRAY_AGG集約関数は、代入文の右側にあるスカラー・サブクエリの選択リスト中で使用することができます。
SET bonusList = SELECT ARRAY_AGG(salary * 0.18) FROM EMPLOYEE;
また、ARRAY_AGG集約関数はSELECT INTO文の選択リストの中で使用することもできます。
SELECT ARRAY_AGG(salary ORDER BY salary) INTO salaryList FROM EMPLOYEE;
ARRAY_AGG集約関数を使用する場合、選択の行数は代入が行われている配列データ型の最大多重度を超えることはできません。これはプロシージャが実行されるときに強制されます。
すべてをまとめると、以下に示すように本記事で前述したgetWeekendsプロシージャを単一のSQL文で書き直した例が出来ます。入力配列はUNNESTを使ってクエリが行われ、結果列はARRAY_AGG集約関数で配列に集約されています。
例題の入力: ['2010-04-24', '2010-02-12', '2010-03-14']
例題の出力: ['2010-04-24', '2010-03-14']
drop procedure getWeekends2;
create procedure getWeekends2(in myDates dateArray, out weekends dateArray)
begin
select ARRAY_AGG(dateColumn) into weekends
from UNNEST(myDates) as dateTable(dateColumn)
where DAYOFWEEK(dateColumn) in (1, 7);
end;
Javaで配列パラメータを使う
プロシージャを呼び出すためにCallableStatementインターフェースを使用する場合、配列パラメータが使えます。Javaオブジェクトの配列は入力パラメータとして使用でき、出力パラメータはJavaオブジェクトの配列に変換できます。
下記のコード例5は、getWeekendsプロシージャを呼び出すクライアントJavaプログラムを示しています。この例では、IBM Toolbox for Java JDBC driver固有のクラスを使用していて、Javaクラスパスにjt400.jarがあることが必要です。
TestWeekends
public class TestWeekends {
public static void main(String[] args) {
AS400 as400 = new AS400("mysystem", "username", "password";
AS400JDBCDataSource ds = new AS400JDBCDataSource(as400);
try {
AS400JDBCConnection connection =
(AS400JDBCConnection)ds.getConnection();
DateFormat df = new SimpleDateFormat("yyyy-MM-dd");
java.sql.Date[] myDates = new java.sql.Date[4];
myDates[0] = new java.sql.Date(df.parse("2004-01-01").getTime());
myDates[1] = new java.sql.Date(df.parse("2005-01-01").getTime());
myDates[2] = new java.sql.Date(df.parse("2006-01-01").getTime());
myDates[3] = new java.sql.Date(df.parse("2007-01-01").getTime());
// Java配列に基づいて新しいメソッドAS400JDBCConnection.createArrayOfを使い
// 配列入力パラメータを作る
java.sql.Array inputArray =
connection.createArrayOf("DATE", myDates);
CallableStatement cs =
connection.prepareCall("{call getWeekends(?, ?)}");
cs.setObject(1, inputArray); // Input array入力配列
cs.registerOutParameter(2, java.sql.Types.ARRAY); // 出力配列Output array
// プロシージャを呼び出して出力パラメータを得る
boolean returnCode = cs.execute();
java.sql.Array weekends = cs.getArray(2);
// 出力パラメータをJava配列に変換する
java.util.Date[] javaWeekends;
javaWeekends = (java.util.Date[])weekends.getArray();
// 期待される出力: 2005-01-01, 2006-01-01
for(int i=0;i<javaWeekends.length;i++)
System.out.println(df.format(javaWeekends[i]));
return;
} catch (SQLException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
}
▲コード例5
これは新しくサポートされた関数のすべてを例示してはいませんが、取っ掛りとしては十分なはずです。また、配列パラメータをもつ外部プロシージャを実装するのにもJavaを使用できますが、その例は本記事の範囲外です。配列データ型の機能強化を含む7.1のJDBCの機能強化についてのもっと詳細な記述は、InfoCenterの「IBM Toolbox for Java JDBC support for IBM i 7.1に対する機能拡張」というトピックの下にあります。
カタログ情報
配列データ型の情報はQSYS2データベース・カタログで利用できます。QSYS2.SYSTYPES表にはシステム上の各配列データ型につき1つの行が含まれています。METATYPE列は、配列データ型に対して’A’、ユーザー定義のディスティンクト型に対して’U’、組み込みシステム型に対して’S’という値を含んでいます。
次のクエリは、システム上のすべての配列データ型に対するすべてのSYSTYPES情報を選択します。
select user_defined_type_schema,
user_defined_type_name, source_type,
length, ccsid, maximum_cardinality
from qsys2.systypes where metatype = 'A'
| SCHEMA | TYPE_NAME | SOURCE_TYPE | LENGTH | CCSID | MAXIMUM_CARDINALITY |
|---|---|---|---|---|---|
| TBLAMER | INTARRAY | INTEGER | 4 | – | 10 |
| ARRXML1 | REAL_ARRAY | FLOAT | 4 | – | 100 |
| TRE | VARCHAR100_ARRAY | VARCHAR | 100 | 37 | 1000 |
| TRE | GRAPHARRAY | GRAPHIC | 10 | 835 | 100 |
カタログ表に関する更なる情報は、Db2 for i SQL解説書の中の「Db2 for iカタログ・ビュー」で見つけられます。
IBM i開発者のためのメモ
-
Db2 for i 7.1にはQAQQINIパラメータという新しいオプションがあります。デフォルトでは、クエリ中にDb2 for iが配列の参照に出会うと、クエリ最適化機構はその配列の一時コピーを作成します。これは強制的にクエリの結果を予測可能なものにするための機能強化でした。カーソルが配列の参照をしている状態でオープンされていて(例えば、WHERE Column1 = myArray[1])、かつ配列値が2つのカーソルフェッチ(myArray[1] = ‘abc’)の間に変更されたとしたら、クエリの結果は予測不能になるかも知れないと想像できるでしょう。
ALLOW_ARRAY_VALUE_CHANGESというQAQQINIのパラメータは、この振る舞いを制御するための切り替え機能を提供します。デフォルト値は’*NO’(つまり、配列の変更を許さず、常に一時コピーを作成する)です。
配列の実装で(SET文またはARRAY_AGG関数のどちらかで)配列要素に値が設定されるようになっていて、かつ値が設定されたなら、配列要素は絶対に変わりません。ALLOW_ARRAY_VALUE_CHANGESは支障なく*YESに設定できます。しかし、最適化機構は依然として小さな配列の一時コピーを作ると判断するかも知れません。
- Db2 for iのCLOB、BLOB、DBCLOB、およびXML配列用の要素毎の最大長は1MBに制限されています。
- デバッグコマンドの中で配列を使用するには特別な規則が適用されるものの、配列値はSQLプロシージャ用のデバッグ中で表示できます。詳細情報は「IBM iデータベース SQL プログラミング」で入手可能です。
-
データベース・モニター・ファイルには、SQLクエリ内の配列変数を記述するための新しい型のレコードが含まれています。新しいレコードのIDは3011です。データベース・モニター・ファイルを作るためにSTRDBMONコマンドを使用し、モニターが配列を使っているプロシージャを捕捉すると、その配列情報を見るために(QQRID = 3011)でクエリにフィルターを掛けることができます。
次の例のクエリは、配列用の新しいモニターフィールドのいくつかを強調しています。更なる詳細情報は、マニュアル「IBM i データベース・パフォーマンスおよびQuery最適化」の「データベース・モニターのフォーマット」というトピックで入手できます。
Select QQC101 AS array_name, QQI1 AS max_cardinality, QQI2 AS cardinality, QQI3 AS index_position, VARCHAR(QQDBCLOB1, 100) as array_values from userlib.mydbmon where QQRID = 3011
例題のモニターでは、配列はUNNESTで使われてきましたから、索引の位置の値(QQI3)はゼロに設定されます。
ARRAY_NAME MAX_CARDINALITY CARDINALITY INDEX_POSITION ARRAY_VALUES Array_1 100 4 0 [‘A00’, ‘D11’, ‘D21’, ‘E11’] -
System iナビゲーター内のSQLパフォーマンス・モニター・サポートは、Visual Explainで配列使用の分析を行う容易な方法です。
System i ナビゲーター7.1のVisual Explainは、データベース・モニター情報を使ってUNNESTおよびARRAY_AGGに関する詳細情報を提供します。下に示す図1は、UNNEST関係を説明するVisual Explainの新しいアイコンを示しています。
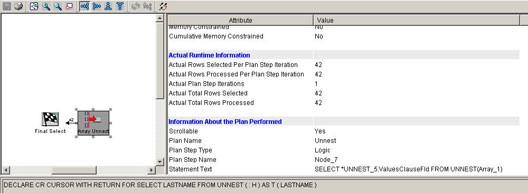
▲図1
SQLパフォーマンス・モニターに取り掛かるために、InfoCenterの「System iナビゲーターを使用した詳細モニターの使用」の章を参照してください。
新たな拡張
ここまで読み進めたなら、あなたはDb2 for i 7.1の配列データ型を活用し始めるのに必要な情報をもう手にしています。配列データ型は、アプリケーション用のプロシージャ・インターフェースを実装するための新しいツールを提供します。配列データ型サポートは、 現代のデータベース標準との互換性を提供するためのIBM i 7.1の新しい主要なSQL機能の1つに過ぎません。
本記事は、配列データ型を定義し、SQL PLとJavaの両方で配列を作成し、新しいSQL関数で配列変数を操作するプロセスについて取り上げました。配列はUNNEST表関数を使って容易に表に変換できますから、クエリを実行することも、他の表と結合することもできます。ARRAY_AGG集約関数は、配列をクエリの選択リストの一部として作成できるようにする新しい集約関数です。
この記事の中の例題では、幾つかの典型的な使い方および構文の変異形を取り上げましたが、いつものように、信頼できる情報源はIBM i Information Centerです。あなたが7.1に更新する理由の1つに配列サポートがあるかどうか分かりませんが、IBM iの統合データベースシステムは新しい機能拡張を続けます。
謝辞この記事をレビューしてくれたJohn Broich、John Eberhard、Theresa Euler、Scott Forstie、Gina Whitneyに感謝します。Scottはいくつかのコード例を提供もしてくれました。